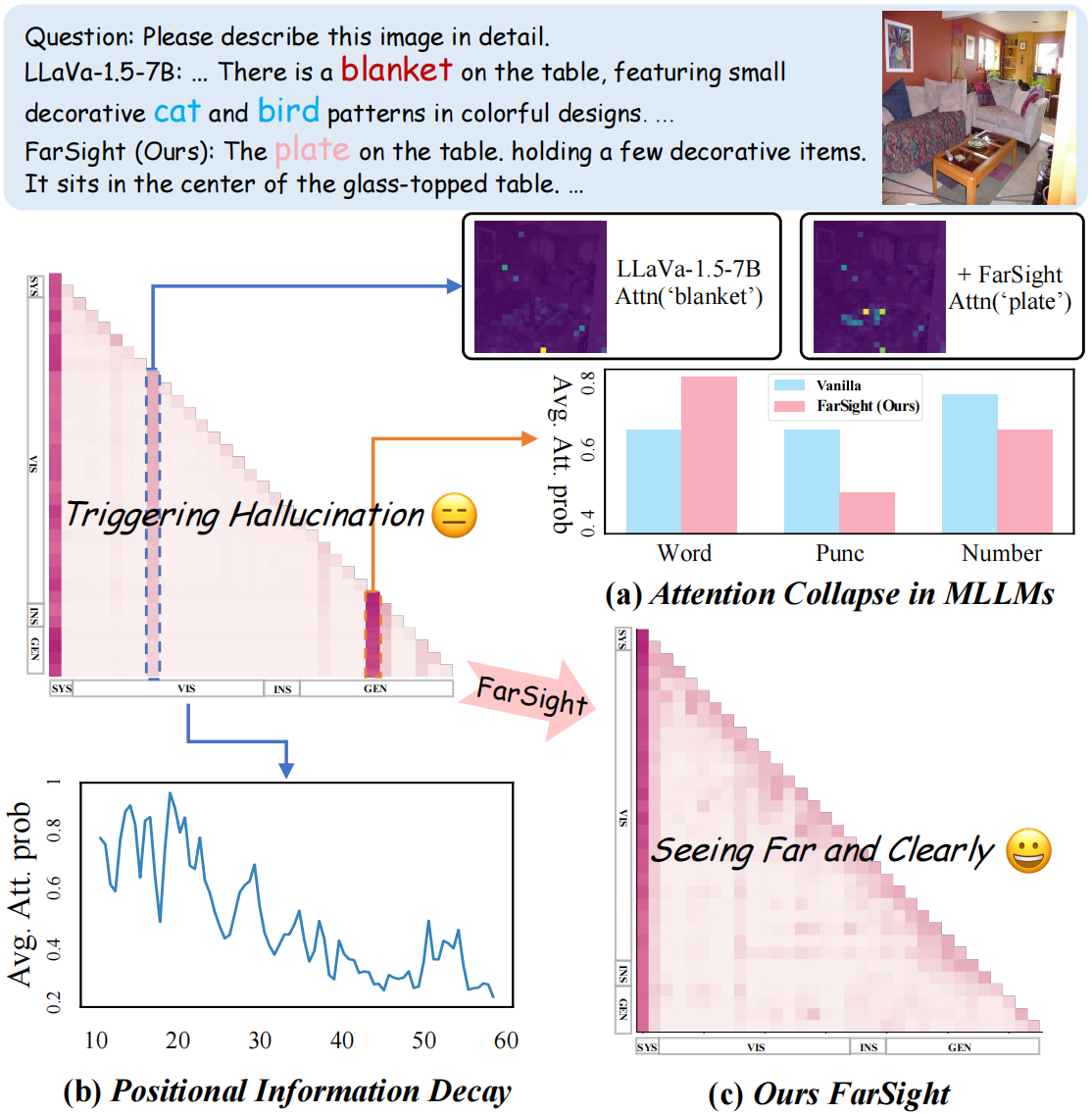
Abstract
Recent advancements in multimodal large language models (MLLMs) have significantly improved performance in visual question answering. However, they often suffer from hallucinations. In this work, hallucinations are categorized into two main types: initial hallucinations and snowball hallucinations. We argue that adequate contextual information can be extracted directly from the token interaction process. Inspired by causal inference in decoding strategy, we propose to leverage causal masks to establish information propagation between multimodal tokens. The hypothesis is that insufficient interaction between those tokens may lead the model to rely on outlier tokens, overlooking dense and rich contextual cues. Therefore, we propose to intervene in the propagation process by tackling outlier tokens to enhance in-context inference. With this goal, we present FarSight, a versatile plug-and-play decoding strategy to reduce attention interference from outlier tokens merely by optimizing the causal mask. The heart of our method is effective token propagation. We design an attention register structure within the upper triangular matrix of the causal mask, dynamically allocating attention capture attention diverted to outlier tokens. Moreover, a positional awareness encoding method with a diminishing masking rate is proposed, allowing the model to attend to further preceding tokens, especially for video sequence tasks. With extensive experiments, FarSight demonstrates significant hallucination-mitigating performance across different MLLMs on both image and video benchmarks, proving its effectiveness.
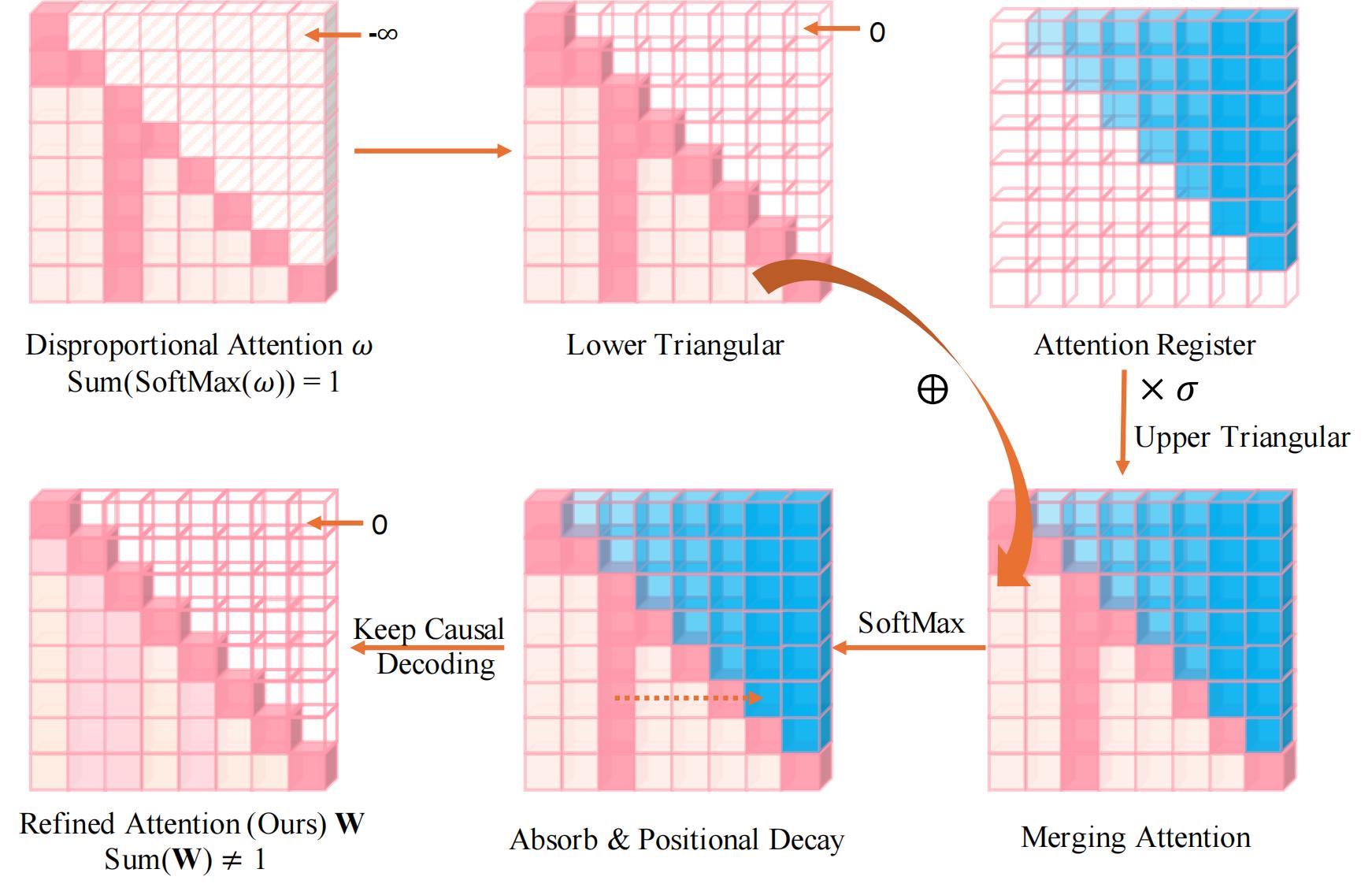
Methodology
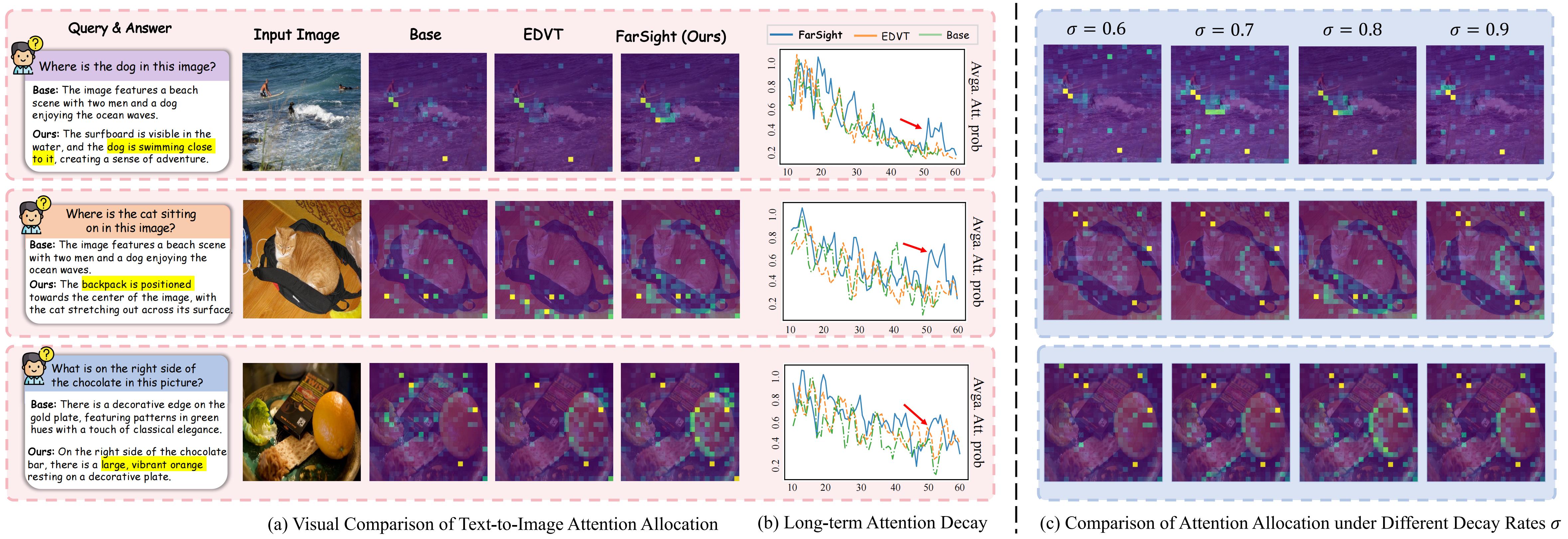
Visualization
BibTeX
@inproceedings{tang2025seeing,
title={Seeing Far and Clearly: Mitigating Hallucinations in MLLMs with Attention Causal Decoding},
author={Tang, Feilong and Liu, Chengzhi and Xu, Zhongxing and Hu, Ming and Huang, Zile and Xue, Haochen and Chen, Ziyang and Peng, Zelin and Yang, Zhiwei and Zhou, Sijin and others},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={26147--26159},
year={2025}
}